
Salom hurmatli seoshniklar! Saytni rivojlantirishning siri nimada, bugungi mavzu aynan shu haqda bo’ladi…
Bugun men juda muhim mavzuni tahlil qilishga qaror qildim. Biz qanday qilib saytning semantik yadrosini to’g’ri tuzish, uni guruhlarga bo’lish va keraksiz, yaroqsiz so’rovlardan tozalash haqida gaplashamiz. Agar siz semantik yadro nima ekanligini bilmasangiz, “Semantik yadro nima va u veb -sayt targ’ibotiga qanday ta’sir qiladi?” nomli materialni diqqat bilan o’qib chiqishni maslahat beraman.
- Semantik yadro oddiy so’zlarda
- Semantik yadroni tuzish usullari
- Key Kollektor
- Yandex Wordstat
- Yandex Wordstat + SlovoYob
- Onlayn xizmatlar
- Mutaxassislarga buyurtma berish
- Semantikani tuzish shartmi?
- Qanday qilib semantik yadroni bosqichma -bosqich to’g’ri tuzish kerak?
- Boshlang’ich asosiy kalitlarni yig’ish
- SlovoYob / Key Kollektor yordamida asosiy so’rovlarni yig’ish
- Haqiqiy chastotani olish
- So’rovlarni klasterizatsiyalash
- Qo’shimcha so’rov (quyruq, dum) qidirish
- Xulosa
Semantik yadro oddiy so’zlarda
Semantik yadro – bu saytingiz mavzusini aniqlaydigan so’zlar va so’z birikmalari. Qoidaga ko’ra u, siz resursingizni to’g’ri to’ldirishda ishlatilishi kerak bo’lgan kalit so’zlar to’plami. Semantik yadro tuzilgach, fayl texnik topshiriq (TT) bilan shug’ullanadigan shaxsga beriladi. U har bir kalit so’zga alohida texnik topshiriq (TT) tayyorlaydi va TT ni maqola yozish uchun koperayterga beradi. Koperayter esa, TT dagi kalit so’zlar va iboralarni matnga to’g’ri joylashtirgan holda maqolani yozadi.
Tijorat saytlari uchun ham bu zanjir deyarli bir xil bo’ladi.
Ikkala holatda ham, kalit so’zlar sayt meta teglarida yoziladi. Bu veb -resursni qidiruv tizimlarida malakali targ’ib qilishning zarur shartlaridan biridir.
Siz, ehtimol, bu so’zlar va iboralar foydalanuvchilarning qidiruv tizimlarida qidirayotgan narsalariga bog’liqligini taxmin qilgan bo’lsangiz kerak albatta. Ya’ni, agar biz «chiroyli divan sotib olish» va «divan do’konlari» so’rovlarini misol qilib oladigan bo’lsak, ulardan biri uchun so’rovlar soni (chastota) yuqori bo’lishini taxmin qilishimiz mumkin. Shunga ko’ra, qidiruv tizimlari sizning resursingizni so’rov natijalarida ko’rsatishi uchun, divan sotish bilan shug’ullanuvchi onlayn-do’kon sayti ma’lumotiga “Chiroyli divan sotib olish” kalitini qo’shish kerak bo’ladi.
Semantik yadro yoki semantika – bu ko’p turdagi so’rovlar ro’yxati bo’lib, odatda ma’lum bir turga ko’ra guruhlarga bo’linadi. Bunday guruhlarga bo’linishi klasretizatsiya deyiladi va deyarli barcha mutaxassislar semantikani klasterizatsiya qilishadi, ya’ni guruhlarga ajratishadi. Bu nafaqat yaxshi TT tuzishga, balki aynan qaysi turdagi so’rovlarni ilgari surilishini aniqlashga yordam beradi.
Semantik yadroni tuzish usullari
Key Kollektor
Semantikani tuzish uchun biz, semantik yadroni tuzish uchun mo’ljallangan dasturlardan foydalanishimiz mumkin. Ulardan ba’zilari sizning o’rningizga deyarli barcha ishni bajaradi – bunday dasturlar avtomatik deb ataladi. Ba’zi dasturlarda esa, siz ko’proq mustaqil ishlashingizga to’g’ri keladi.
Masalan, Key Kollektor deb nomlangan pullik dastur mavjud. Garchi bu dastur deyarli to’liq avtomatlashtirilgan bo’lsa-da, siz Key Kollektorni qanday sozlashni bilishingiz kerak. Ishga tushirganingizdan keyin, bu dastur barchasini o’zi avtomatik ravish bajaradi. Siz faqat, ishning oxirida, kalitlardan eng foydasizlarini olib tashlashingiz, ya’ni so’rovlarni ozgina tozalashingiz kerak, tozalashga, robotlar, spam va hokazolarning so’rovlari kiradi. Bunday dasturning narxi deyarli 2000 rublni tashkil qiladi.
Yandex Wordstat
Bundan tashqari, Yandex – Wordstat xizmatidan foydalanib, semantikani to’plashingiz mumkin. Foydalanish juda oson, siz kalit so’zni kiritib qidiruv tugmasini bosasiz, u sizga ushbu kalit mavjud bo’lgan barcha so’rovlarni ko’rsatadi. Shu bilan birga Wordstat, asosiy kalitga o’xshash so’rovlarni ham ko’rsatadi.
Ushbu maqolada, Wordstat yordamida, asosiy semantik yadroni tuzishimiz uchun kerak bo’ladigan boshlang’ich so’rovlarni yig’amiz. Bu haqda keyinroq, lekin hozircha men sizga semantikani to’plashning yana bir qancha usullarini aytib o’taman.
Yandex Wordstat + SlovoYob
SlovoYob – bunday antiqa ismli dastur Key Kollektor-ning mutlaqo bepul analogidir. Tabiiyki, unda KeyKollektorga qaraganda biroz kam funksiyasi bor, lekin shu funksiyalar ham, semantik yadroni yig’ish uchun etarli.
Agar siz SlovoYob -ning Key Kollektor -dan qanday farq qilishini bilmoqchi bo’lsangiz, ushbu jadvalga qarang:
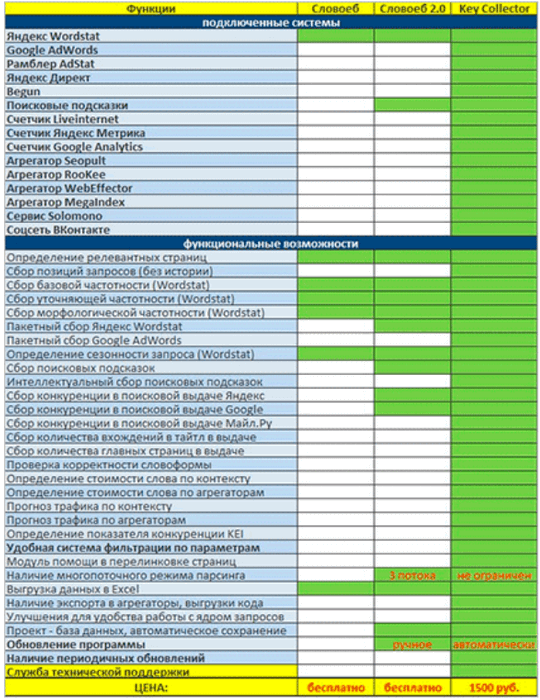
Albatta, bu erdagi farq –yer bilan osmon qadar. Biroq, oddiy yadroni yig’ish uchun SlovoYobning imkoniyatlari etarli.
Onlayn xizmatlar
Shunday qilib, yuqoridagi variantlarga qo’shimcha ravishda, semantikani onlayn xizmatlar yordamida yig’ish ham mumkin. Agar siz qidiruvga “Сбор семантики онлайн” so’rovini kiritsangiz, qidiruv tizimi sizga har xil turdagi onlayn vositalarni ko’rsatadi. Ular ham yaxshi, ham yomon bo’lishi mumkin. Va shunga ko’ra, ham pulli, ham bepul.
Turli xil onlayn xizmatlar yordamida siz, raqobatchilarning semantik yadrosini bilib olishingiz mumkin. Dunyoda deyarli barcha kompaniyalar raqiblarining ochiq ma’lumotlarini tekshiradilar, tahlil qiladilar.
Mutaxassislarga buyurtma berish
Mutaxassisdan tayyor yadroni sotib olishingiz mumkin. Mutaxasis barcha so’rovlarni yig’adi va so’rovlar yig’ilgan faylni sizga topshiradi. Va bu fayldagi kalit so’zlar asosida, maqola yozish uchun texnik topshiriq (TT) tayyorlanadi. Va tayyor TT, maqola yozish uchun koperayterga beriladi. Bu endi, ishlarni taxsimlashga kiradi. Biz bu mavzuga bugun tegmaymiz, boshqa maqola doirasida ko’rib chiqamiz.
Semantikani tuzish shartmi?
Agar siz ushbu maqolani o’qiyotgan bo’lsangiz, demak sizni ham bu savol qiziqtiradi. Semantikani yig’ish dastlab juda qiyin vazifa bo’lib tuyuladi. Qolaversa, ba’zi vebmasterlar buning nima uchun zarurligini har doim ham tushunishavermaydi.
Agar biz pul topish uchun yaratilgan blog yoki sayt haqida gapirayotgan bo’lsak, unda bunday loyihalar mualliflarida “aslida qaerdan ilhom olish kerak va umuman nima haqida yozish kerak” degan oqilona savol tug’iladi. Agar sizda barcha mavzular va kalit so’zlar yozilgan tayyor elektron jadval bo’lsa, unda siz o’z materialingizni nima haqida yozishni aniq bilasiz. Bu yondashuv nafaqat tezlikni sekinlashtirishga, balki uni oshirishga ham imkon beradi, chunki keyingi maqolaning mavzusini o’ylab, bosh qotirishingiz shart bo’lmaydi. Faqat ro’yxatdagi mavzulardan birini tanlab, materialni qanday yozishni o’zingiz hal qilishgina qoladi xolos.
Shunday qilib, sizning barcha maqolalaringiz (agar matn to’g’ri yozilgan, kalit so’zlar joyida va to’g’ri ishlatilgan bo’lsa) qidiruv tizimlarida yaxshi o’rinni egallaydi, bu esa loyihangizga tashrif buyuruvchilar sonini ko’paytirishni ta’minlaydi va sizga yangi marralarni egallashga motivatsiya berib, qiziqishingizni oshiradi. Quvonarli, to’g’rimi? Bu quvonchlarning barchasi, yig’ish uncha ko’p vaqtingizni olmaydigan bitta element – semantika tufaylidir.
Agar biz tijorat saytlari (lending, onlayn-do’konlar va h.k.) haqida gapiradigan bo’lsak, semantik yadroni yig’ish bu, zaruriyat. Ochig’ini aytganda, semantikasiz boshqa hech qanday yo’l yo’q, yaxshisi bunday saytni ochmagan ma’qul. Resursni kontent va meta teglar bilan to’ldirishda ham, kontekstli reklama berishda ham, bizga albatta semantika kerak bo’ladi, biznesimizning rivojlanishi faqat shunga bog’liq.
Bitta SlovoYobning o’zi, butun semantikani yig’ishga kamlik qiladi. Agar biz biznesimizni to’laqonli rivojlantirishni, semantikani to’liq tuzishni istasak, SlovoYobning Key Collektor deb nomlangan kengaytirilgan versiyasini sotib olishimiz kerak. Dasturda turli xil kontekstli tarmoqlar (Direct, Adwords va boshqalar) bilan ishlash uchun mo’ljallangan juda ko’p turli funksiyalar mavjud (yuqoridagi jadvalda ko’rgansiz).
Xulosa qilib aytadigan bo’lsak, semantika tuzishga arziydi. Bu sizning loyihangizni targ’ib qilish sifatini oshiradi va sizga, kontent reja tuzishda, foydalanuvchilarning ehtiyojlari haqida ancha yaxshi ma’lumot olish imkonini beradi.
Qanday qilib semantik yadroni bosqichma -bosqich to’g’ri tuzish kerak?
Biz semantik yadroni besh bosqichda tuzishga harakat qilamiz. Bularga quyidagilar kiradi: asosiy kalit so’zlarni qidirish va tanlash, ularni SlovoEB yoki Key Kollektor dasturida tahlil qilish (men birinchi variantdan foydalanaman), har bir so’rov uchun chastota (nechi marta so’ralgan) ni aniqlash, qo’shimchalar (quyruq) ni yig’ish, ya’ni asosiy kalit so’z tarkibida mavjud bo’lgan qo’shimcha so’rovzlar.
Masalan: “Toshkentda onlayn ravishda qora rangli divan sotib olish”, bu erda asosiy kalit, qalin qora rang bilan ajratilgan va so’rovdagi qolgan boshqa so’zlar barchasi qo’shimcha ya’ni quyruq hisoblanadi. Agar bizning maqolalarimizda nafaqat asosiy so’rov, balki ularning quyruqlari ham ishtirok etsa, demak, aynan bizning shu materialimizni foydalanuvchilar, ushbu iboralarning turli xil variantlari orqali topib kelishlari mumkin.
Xo’sh, keling endi semantika tuzishni qadamba-qadam boshlaymiz…
Boshlang’ich asosiy kalitlarni yig’ish
Boshlang’ich asosiy kalitlarni yig’ish uchun biz, Wordstat-dan foydalanamiz. Ammo bundan oldin biz, qanday mavzularda maqola yozishimiz yoki targ’ib qilishimizni mustaqil ravishda aniqlab olishimiz kerak. Men o’zim uchun quyidagi mavzularni yozaman:
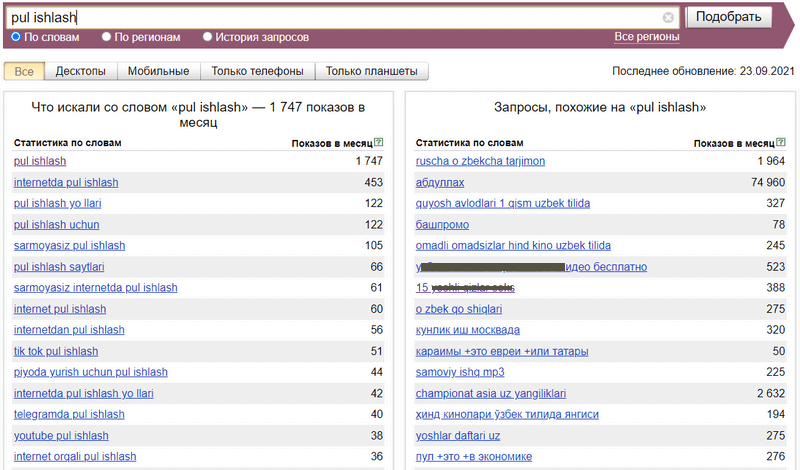
- pul ishlash
- daromad,
- Moliya,
- frilanser,
- maqola yozish.
O’ylaymanki, misol qilish uchun 5 dona etarli bo’ladi. Sizning holatingizda, bu mavzular ko’proq bo’lishi mumkin. Boshlang’ich asosiy kalitlarni yig’ishda siz, sayt bo’limlari sarlavhalaridan yoki shu bo’limlarga yozilajak maqolalar sarlavhalaridan foydalanishingiz mumkin.
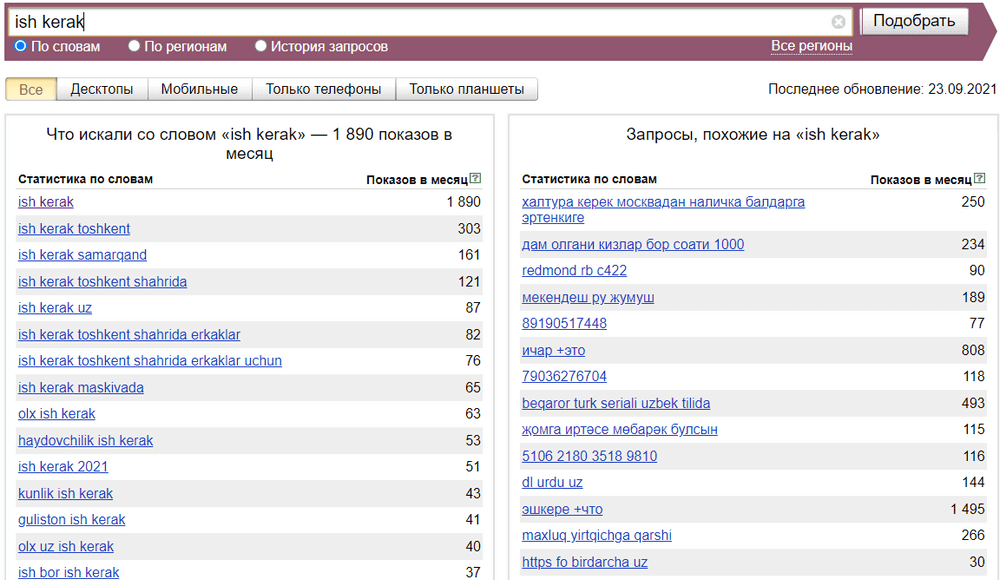
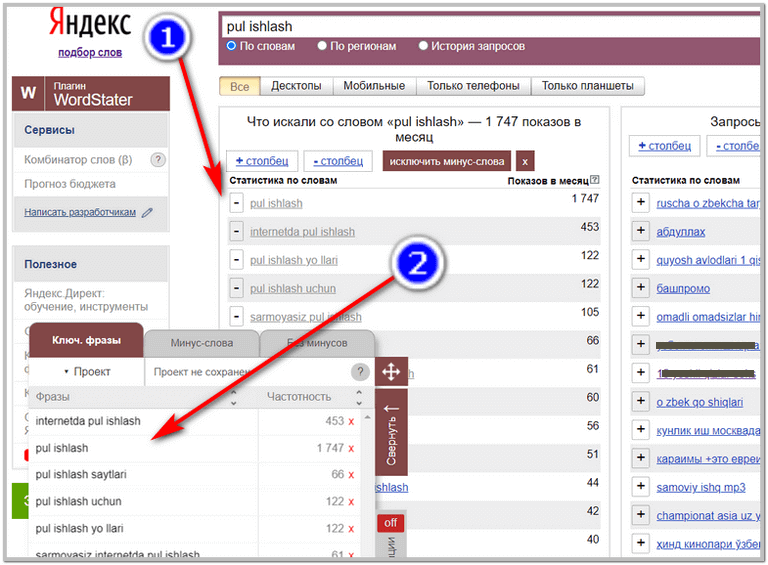
Endi biz birinchi so’zni olamiz va Wordstat-ga qo’yib qidiruv beramiz. Xizmat bizga ko’p sonli turli xil so’rovlarni chastotasi (nechi marta qidirilganligi) bilan ko’rsatadi, ya’ni Yandex qidiruv tizimiga aynan shunday so’zlar bilan qilingan so’rovlar soni. Bu shunday ko’rinishda bo’ladi:
Ko’rib turganingizdek, bu erda ko’plab variantlar mavjud. Xizmat bizga pul ishlash so’zi bilan bog’liq eng mashhur so’rovlarni ko’rsatdi. O’ng tomonda esa, bizga yoqishi mumkin bo’lgan o’xshash variantlarni ham ko’rsatdi.
Xo’sh endi, shu yerda to’xtab, “internetda pul ishlash”, “pul ishlash yo’llari” kabi kalit so’zlardan foydalanib, maqola yozish va minglab o’quvchilar bizning noyob asarimizni (shedevr) o’qish uchun yopirilib kelishini kutish, bu albatta katta xato.
Aytgancha, brauzeringizga manabunday plaginni o’rnatib oling:
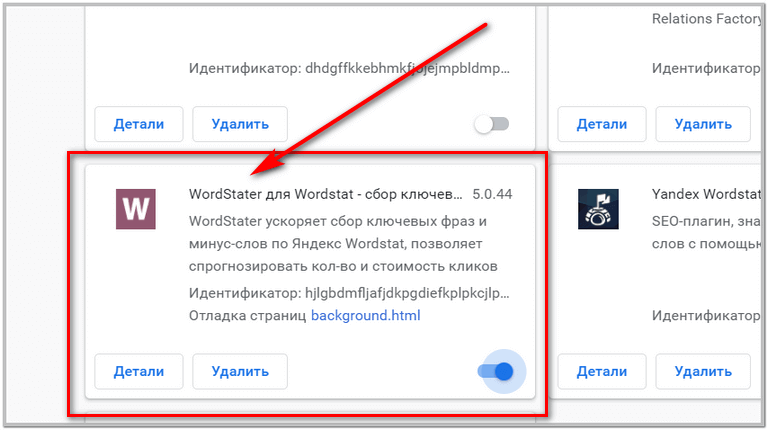
Bu plagin Wordstat bilan ishlashingizni osonlashtiradi. Uni o’rnatganingizdan keyin, kalit so’zlar yonida (+) paydo bo’ladi. Qaysi kalit sizga ma’qul va kerak bo’lsa, shu kalit so’z to’g’risidagi (+) ga bossangiz, kalit so’z chap tomonda joylashgan plagin oynasida paydo bo’ladi. Va siz barcha maqul kalitlarni olganingizdan keyin, oynachadagi barcha kalitlarni birdaniga kopiya qilib olasiz va alohida faylga saqlab qo’yasiz. Aks holda bittalab olishingizga to’g’ri keladi:
Demak, mavzuga qaytamiz…
Shunday qilib, semantik yadroni tuzish biz o’ylaganchalik oson emas, yuqoridagi Wordstat-da berilgan kalitlar yuqori chastotali kalitlardir. Bunday kalitlar bilan biz, yuqori o’rinlarni egallay olmaymiz. Va bularni kerakmasga ham chiqarmaymiz, eng natijali rivojlanish, barcha turdagi kalit so’zlarni teng ishlatishdadir.
Endi biz yuqorida o’zimiz o’ylab topgan boshlang’ich kalit so’zlarning qolgan barchasini ham xuddi “Pul ishlash” kalit so’zini ishlatganimizdek, ularga oid so’rovlarni ham yig’ib, bir faylga joylashtiramiz. Wordstat-ning o’ng oynasidagi so’rovlardan ham o’zimizga keraklilarini yig’ib olamiz.
Birinchi qadamdan so’ng, bizda, bizning fikrimizcha va Wordstat fikriga ko’ra, eng mazali bir necha o’nlab so’rovlar ro’yxati bo’lishi kerak. So’rovlarning yozilishi jihatidan tushunarlilarini tanlab olishga harakat qiling. Menimcha bu yerda hech qanday muammo bo’lmasligi kerak.
Ro’yxatimiz taxminan quyidagi ko’rinishga ega bo’lishi kerak:

SlovoYob / Key Kollektor yordamida asosiy so’rovlarni yig’ish
Endi biz eng qizig’iga o’tamiz. SlovoYob yoki KeyKollektor yordamida barcha asosiy so’rovlarning turli ko’rinishlardagi qo’shimcha va sinonimlarini yig’ib olishimiz kerak.
KeyKollektor hammada ham bo’lmasligini hisobga olib, men barchasini SlovoYobda bajarib ko’rsataman. Birinchi navbatda dasturni bu yerdan yuklab oling va kompyuteringizga o’rnating, keyin dasturni sozlang.
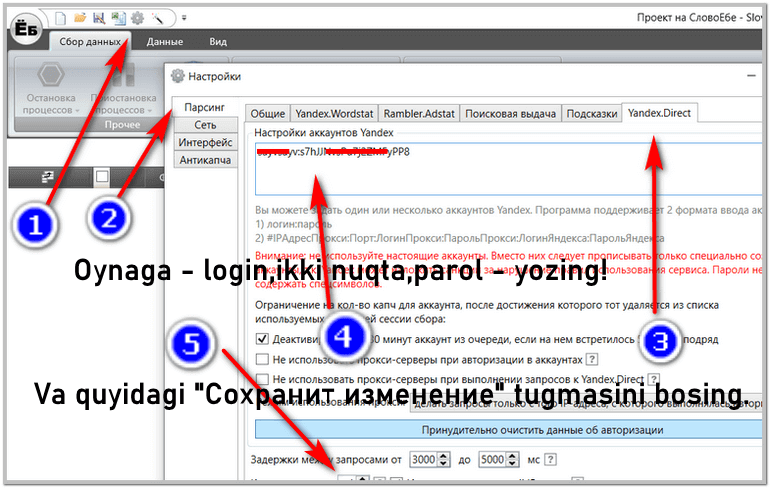
Sozlash uchun yangi Yandex pochta ochishimiz kerak va pochtaga kirish ma’lumotlarimizni SlovoYob-dagi maxsus joyga kiritishimiz kerak bo’ladi. Yangi pochta ochishimizdan maqsad, agar bizga Yandex zapret qo’yadigan bo’lsa ham yangi pochtamiz zapret bo’ladi. Kerakli pochtani bu yerga kiritmagan ma’qul.
Quyidagi rasmdagiga qarab sozlab oling, login va parol o’rtasiga ikki nuqta qo’yasiz, masalan, login:parol , xuddi shunday qilib yozing va quyidagi “Сохранить изменение” tugmasiga bosing:
Demak davom etamiz…
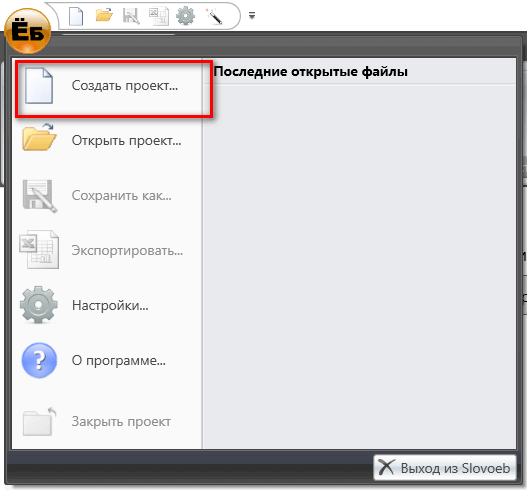
Dasturni o’rnatib, sozlaganingizdan keyin, asosiy oynadagi yoki yuqori menyudagi tugma yordamida yangi loyiha ochamiz:
Loyiha yaratilgandan so’ng, siz Wordstat orqali semantikani yig’ishni boshlashingiz kerak (Quyidagi rasdagi 1 raqami bilan ko’rsatilgan tugmalarning, qizil tugmasi Worstat ning chap ustunidan va ko’k tugma o’ng ustunidan ma’lumot yig’adi, uchta dumaloqli tugma esa, qo’shimcha kalitlarni yig’adi). Qisqacha aytganda, dasturning o’zi Wordstat-ga ulanadi va barcha kerakli ma’lumotlarni yig’adi, siz faqat kerakli tugmani bosasiz.
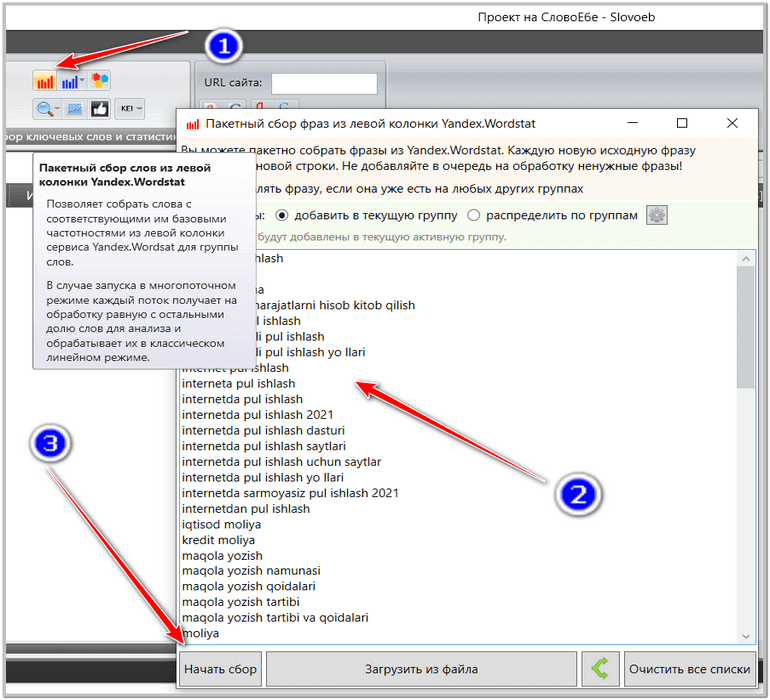
E’tibor bering (yuqoridagi rasm), yig’ish uchun biz Wordstat-ning chap ustunidan foydalanamiz. Chap ustunda, qidiruv tizimlaridagi barcha saytlarning asosiy kalit so’zlari joylashgan. Lekin biz o’ng ustunini ham yig’ishimiz mumkin. Shunday qilib biz, juda katta miqdordagi, turli sortlardagi kalit so’zlarni yig’ib olamiz.
Demak, Wordstatdan yig’ib olgan boshlang’ich kalit so’zlar saqlangan fayldagi barcha kalitlarni dasturda ochilgan oynaga kiritamiz va «Начать сбор» tugmasini bosamiz.
Jarayon boshlanadi va dastur kerakli iboralarni o’z ichiga olgan so’rovlarni qidirishni boshlaydi. Albatta, oynaga kiritgan kalit so’zlar qancha ko’p bo’lsa, shuncha ko’p kalit so’zlar yig’ib olamiz. Lekin, oynaga kiritilgan kalitlar qancha ko’p bo’lsa, dasturning ishlash jarayoni ham ko’p vaqtga cho’zilishi mumkin. Balkim 2-3 soat, bazida sutkalab ham ishlashi mumkin. Shuning uchun men, vaqtni tejash maqsadida bitta «Internetda pul ishlash» so’rovini qoldirdim va jarayonni boshladim. Dasturning menga bergan ma’lumotlari:
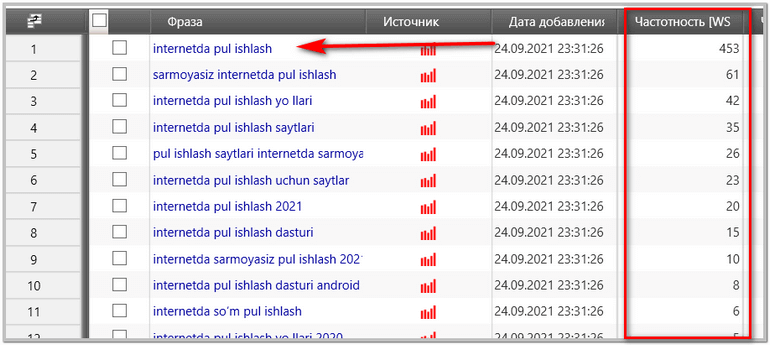
Ko’rib turganingizdek, dastur o’z vazifasini bajardi va men nafaqat turli xil so’rovlarni, balki ularning chastotasiga ham ega bo’ldim. Biroq, xursand bo’lishga shoshilmang. Men qizil to’rtburchak bilan belgilagan ma’lumotlar umuman foydasiz yoki noto’g’ri bo’lib chiqishi ham mumkin. Bu chastotalar befoyda yoki tayanch chastota deb ham ataladi.
Agar siz bu yerdagi tayanch chastotadan foydalanib maqola yozadigan bo’lsangiz, bir necha oy ichida ham maqolani hech kim o’qimasligi mumkin. Shu sababli, biz haqiqiy ma’lumotlarni olishimiz kerak, buning uchun biz dasturning ichki funksiyalaridan foydalanamiz.
Haqiqiy chastotani olish
Chastota nima – har bir so’rovning foydalanuvchilar tomonidan nechi marta so’ralgani.
Kalit so’zlar va iboralarning haqiqiy chastotasini olish uchun biz SlovoYob yoki Key Kollektor-ning o’rnatilgan funksiyalaridan foydalanishimiz mumkin. Ushbu maqolada biz SlovoYob-dan foydalanayotganimiz sababli, men hamma narsani uning misolida tushuntiraman. Key Kollektor-da bu jarayon deyarli farq qilmaydi. Faqat yangi versiyalarda elementlarning joylashuvi o’zgargan xolos. Lekin aminmanki, siz buni aniqlay olasiz.
SlovoYob-da biz quyidagi tugmalardan foydalanamiz, bizga keragi eng quyisidagi:
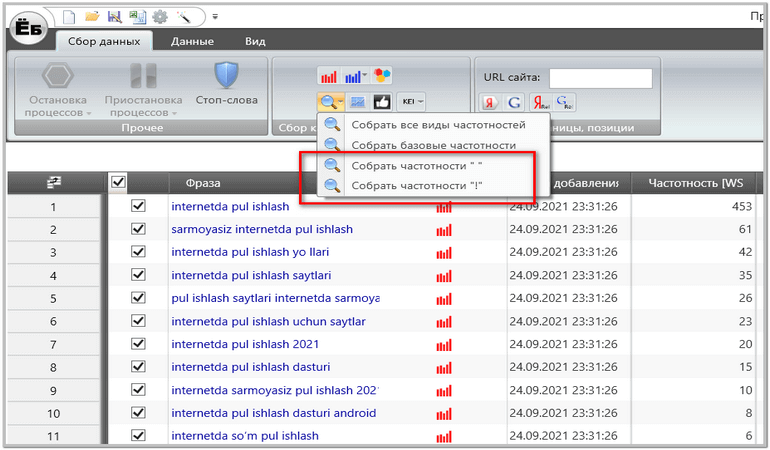
» » – Chastotasi, faqat qo’sh tirnoq ichida joylashgan so’zlarga mos keladi. Qo’shimcha va joylashuvi boshqacha bo’lishi mumkin.
! – Chastotasi, qo’shimcha va so’z joylashuvi o’zgarmas aniq kirish kaliti.
Biz barcha kalitlarni galochka bilan belgilab “Сборь частотность “!” “ yozuviga bosamiz va quyidagi chastotalarga ega bo’lamiz:
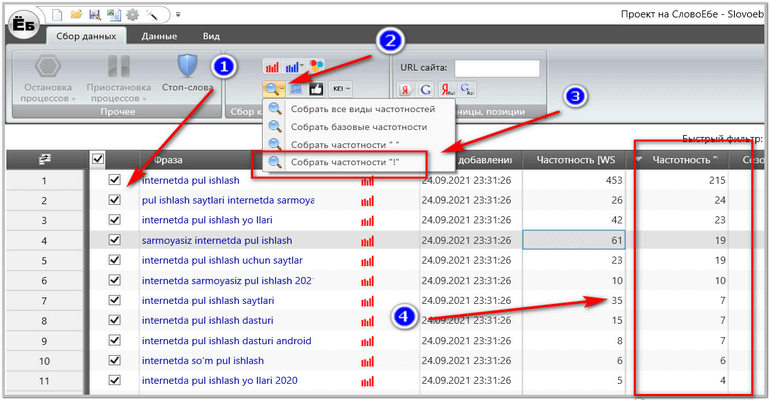
Ikki ustun orasidagi farqni o’z ko’zingiz bilan ko’rishingiz mumkin. «Internetda pul ishlash» so’rovining haqiqiy chastotasi tayanch chastotasidan (birinchi ustun) deyarli 1 baravar kam. Boshqa so’rovlarda bundan ham sezilarli bo’lishi mumkin. Shuning uchun, har safar semantikani yig’ganingizdan keyin, albatta haqiqiy chastotani aniqlaydigan dasturlardan foydalaning.
So’rovlarni tozalash sizga, Yandex foydalanuvchilaridan kelib tushadigan so’rovlar chastotasi to’g’risida ishonchli ma’lumotlarni olish imkonini beradi.
Aniq ma’lumotlarni olish jarayoni tugagach, keraksiz, ya’ni chastota umuman yo’q yoki juda kam (10 tagacha) so’rovlarni topish va ularni alohida papkaga ko’chirish uchun tez filtrdan foydalanishingiz mumkin (bu funksiya SlovoYobda yo’q). Yoki bu ishni qo’lda qilishingiz mumkin.
Bizga foydalanuvchini ko’p olib keladigan kalit so’zlar kerak. Agar saytingiz hali yosh bo’lsa, juda ko’p mashhur saytlar foydalanadigan yuqori chastotali kalitlarni olishga shoshilmang. Bunday chastotalar 1000 dan yuqori bo’lishi mumkin.
Albatta, biz barcha so’rovlarning raqobatbardoshligini ham tekshiramiz. Biroq, agar so’rovlar chastotasi bir necha o’n minglab bo’lsa, undabu so’rov bo’yicha raqobatchilar ham juda ko’p bo’ladi.
So’rovlarni klasterizatsiyalash
Yuqorida aytganimdek, yadro – ko’p turdagi so’rovlar ro’yxati bo’lib, odatda ma’lum bir turga ko’ra guruhlarga bo’linadi. Guruhlarga bo’linishi esa, klasterizatsiya deyiladi.
Endi biz butun semantik yadroimizni, aniqrog’i undagi kalitlarni guruhlarga bo’lishimiz kerak. Men ushbu material doirasida, faqat chastota bo’yicha bo’laman, eng mashhur variant va deyarli hamma joyda qo’llaniladi. Bundan tashqari ma’no mazmun va raqobatbardoshliligi jihatidan ham guruhlarga bo’lish mumkin.
Biz barcha so’z va iboralarni yuqori chastotali (YCH), o’rta chastotali (O’CH), past chastotali (PCH) va mikropast chastota (MPCH) larga bo’lishimiz mumkin. Menimcha, guruhlash tamoyilini tushuntirishga hojat yo’q. Biroq, taxminiy o’lchovlarni ko’rsatish kerak. Runetda bu ko’rsatgichlar taxminan quyidagicha:
- YCH – yuqori chastota – 10 000 dan yuqori so’rov (Bir oyda);
- O’CH – o’rta chastota – 1 000 dan 10 000 gacha;
- PCH – past chastota – 1 000 gacha;
- MPCH – mikro past chastota – 100 gacha.
Bizda aholi sonini va o’zbek tilida gapiradigan va o’zbek tilida internetdan ma’lumot qidiradiganlarni Runet foydalanuvchilari bilan solishtirganda ancha kam bo’lishi mumkin. Mening taxminiy kuzatuvlarim bo’yicha quyidagicha bo’lishi mumkin:
- YCH – yuqori chastota – 1 000 dan yuqori so’rov (Bir oyda);
- O’CH – o’rta chastota – 500 dan 1 000 gacha;
- PCH – past chastota – 500 gacha;
- MPCH – mikro past chastota – 50 gacha.
Raqamlar umumiy qabul qilingan o’ta sub’ektiv va taxminiy. Agar bu ko’rsatgichlarni inkor qiluvchilar bo’lsa, marhamat izohlarda o’z variantlaringizni yozing.
Chastota bo’yicha guruhlash, foydalanuvchilarning nechi marta qidirganliklaridan kelib chiqib, barcha so’rovlarnining guruhlarga aralashmasidek ko’rinadi. Bularni biz oldingi qadamda yigib oldik, endi guruhlarga bo’lishhimiz qoldi xolos.
Bu erda siz so’rovlar chastotasiga emas, balki raqobat asosida, ya’ni aynan shu so’rovlarni ilgari surayotgan saytlar soniga qarab, yana bir nechta guruhlarni bo’lishingiz mumkin.
Yuqori raqobatbardosh (YR), o’rta (O’R) va past raqobatbardosh (PR) so’rovlar mavjud. Biz barcha so’rovlarni aynan shunday turli guruhlarga ajratishimiz mumkin va bu hatto afzalroq bo’ladi. Saytimizni yanada samarali targ’ib qilish uchun bizga eng yuqori chastotali va eng kam raqobatli so’rovlar kerak. Albatta, bu ideal holda.
So’rovlarni guruhlarga bo’lishda avtomatlashtirilgan vositalardan (onlayn xizmatlar), yoki o’z qo’llaringiz bilan amalga oshirishingiz mumkin.
Ozingiz o’ylab ko’ring, minglab so’rovlarga qo’lda ishlov berish – odam jinni bo’lib qolishi mumkin – buning iloji ham yo’q, qolaversa 21 asrda. Sizning asablaringizni asrash maqsadida, barcha kalit so’zlarni guruhlarga bo’lish uchun avtomatik xizmatlardan foydalanishni maslahat beraman.
Internetda bunday xizmatlar unchalik ko’p emas. Juda yaxshilari yanayam kam. Hozirgi kunda, bir necha yillardan buyon Runetda, semantikani yigish va klasterizatsiya qilish bo’yicha ma’qul deb topilgan xizmatlardan biri Muutagenni, men ham sizga tavsiya qilmoqchiman. Uning yordamida, yuqorida aytilgan barcha ishlarni ortig’i bilan bajarish mumkin.
Bu onlayn xizmat pullik, lekin uni ba’zi cheklovlar bilan tekin ishlatish mumkin. Tekshiruv kuniga 10 tadan oshmasligi kerak. Agar pullik versiyasini ishlatganda ham qimmatga tushmaysiz. 100 ta tekshiruv atigi 30 rubl turadi va bir tekshirgan so’rovingizni qayt-qayta tekshirish bepul bo’ladi.
Mutagenni ishlatishda hech qanday muammo bo’lmasligi kerak. U erda barchasi tushunarli, lekin interfeys rus tilida. Bu xizmat bilan ishlash asoslarini tushuntiradigan kichik FAQ ham mavjud. Agar tushunmovchiliklar bo’lsa, izohlarda yozsangiz, bu xizmat yuzasidan alohida maqola yozishim ham mumkin.
Tezroq klasterlash uchun siz ommaviy tekshiruvdan foydalanishingiz kerak. Minglab so’rovlarni bittalab tekshirmaymizku. Ommaviy tekshiruvni amalga oshirish uchun siz xizmatda ro’yxatdan o’tishingiz kerak va shundan keyingina ommaviy tekshirish o’tkazishingiz mumkin.
SlovoYob – da raqobatbardoshlikga oid barcha ma’lumotlarni olib bo’lganingizdan keyin, kalitlarni nusxalaysiz va Mutagenga qo’yib, guruhlarga ajratasiz.
Qo’shimcha so’rov (quyruq, dum) qidirish
Nihoyat, biz eng mazali kalitlarni yig’ib olganimizdan keyin, dumlarni (qo’shimcha) qidirishga harakat qilishimiz kerak. Biz kerakli so’rovni Yandex va Google-ga kiritamiz va ular bizga o’zlari barchasini ko’rsatadi, masalan:
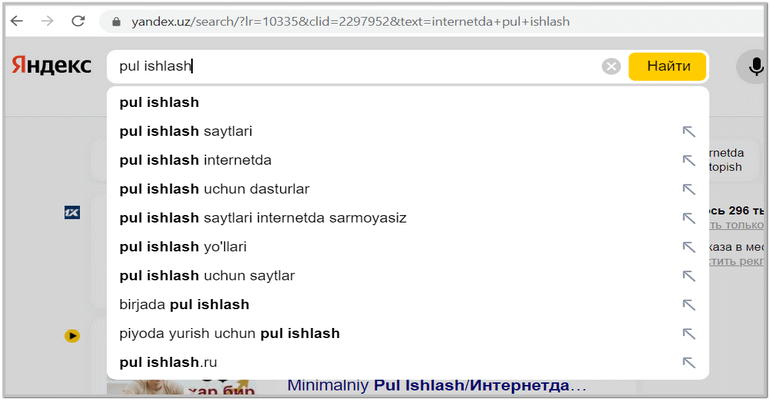
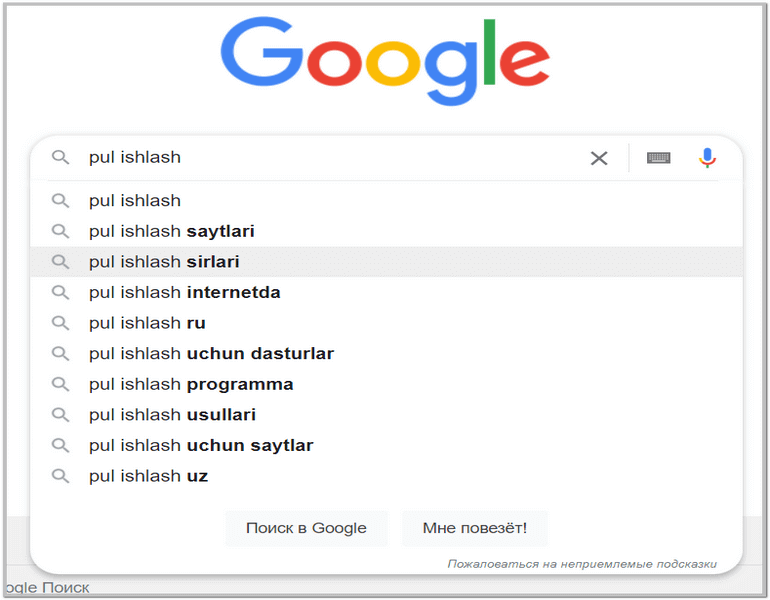
Ko’rib turganingizdek, unchalik ko’p emas. Siz aytishingiz mumkin, o’zi oz ekan, kerakmi shu deb, haqiqatdan ham aqlli Yandex o’zi bizning manbamizni qo’shimcha so’rovlar bilan birga TOPga chiqarmaydimi?((( Balkim chiqarar, qachonki, agar sizning manbangizda shunday quyruqlar ishtirok etgan materiallar bo’lsa, ehtimol sizning saytingiz ushbu so’rovlar natijalarida birinchi TOP-3 dan joy olar.
Qo’shimcha so’rovlar yordamida targ’ib qilish, ayniqsa, yosh saytlar uchun juda muhim. Chunki, bunday manbalarga hali ishonch yo’q, lekin agar maqolaning biron bir joyida kalit bo’lsa, ehtimol Yandex va Google hatto ishonchsiz manbani ham yuqori o’rinlarga qo’yishi mumkin. Qidiruv tizimlari uchun har bir foydalanuvchi o’zi izlagan malumotini olishi muhim. Shuning uchun, semantik yadroingizga quyruqli so’rovlarni qo’shishga arziydi.
Afsuski, dumlarni yig’ish qo’lda bajarilishi kerak. Ammo siz minglab kalitlarning quyruqlarini tahlil qilishga urinmasligingiz kerak. Buni tanlangan holda qiling, tashrif buyuruvchilaringiz uchun nima qiziq bo’lishi mumkinligini yodda tuting.
Xulosa
Ko’rib turganingizdek, semantik yadroni atigi 5 bosqichda yig’ishingiz mumkin. Albatta, bu yo’riqnomada tayanch ma’lumotlarni o’rganishga va eng oddiy semantikani tuzishga yordam beradigan asosiy ma’lumotlar berilgan. Ammo juda jiddiy loyihalar uchun tegishli yondashuv talab etiladi. Masalan, kalit so’zlarni klasterizatsiya qilishda, siz ularni nafaqat YCH va MPCH, yoki YR va PR ga, balki tijorat va notijoratga bo’lishingiz kerak bo’ladi. Yoki hatto mintaqani hisobga olgan holda guruhlarga bo’lish mumkin.
Bularning barchasi, albatta, ko’p vaqt talab etadi, lekin agar siz semantikani mustaqil o’zingiz yig’sangiz, uni tahlil qilsangiz va umuman qidiruv tizimlarida ishlar qanday tashkil topganligini o’rgana borsangiz, vaqt o’tishi bilan sizga asta–sekin tushuncha kela boshlaydi. Siz har xil jarayonlar uchun barcha yangi vositalarni topasiz, semantikani yig’ish va uning guruhlanishini hech qanday qiyinchiliklarsiz tez fursatlarda bajarishingiz mumkin bo’ladi. Agar siz bunga juda qiziqsangiz albatta.
Shu bilan bugungi maqola tugadi, tushunmaganlaringiz bo’lsa, izohlarda qoldiring, albatta tushuntirishga harakat qilaman. Balkim, butun savollarni yig’ib, alohida maqola yozarman. Xayr!
Как правильно структурировать семантическое ядро сайта
Здравствуйте, дорогие сеошники!
Сегодня я решил разобрать очень важную тему. Мы поговорим о том, как правильно структурировать семантическое ядро сайта, разделить его на группы и почистить от ненужных, недействительных запросов. Если вы не знаете, что такое семантическое ядро, прочтите статью «Что такое семантическое ядро и как оно влияет на продвижение сайта?» Советую внимательно прочитать материал.
Семантическое ядро в простых словах
Семантическое ядро – это слова и словосочетания, определяющие тематику вашего сайта. Как правило, это набор ключевых слов, которые следует использовать для правильного наполнения вашего ресурса. После создания семантического ядра файл передается лицу, занимающемуся техническим заданием (ТЗ). Он готовит отдельные ТОС для каждого ключевого слова и отдает ТОС копирайтеру для написания статьи. Копирайтер пишет статью, правильно расставляя ключевые слова и словосочетания в тексте.
Для коммерческих сайтов эта цепочка практически одинакова.
В обоих случаях ключевые слова прописываются в метатегах сайта. Это одно из необходимых условий грамотного продвижения веб-ресурса в поисковых системах.
Вы, наверное, догадались, что эти слова и фразы зависят от того, что пользователи ищут в поисковых системах. То есть, если взять в качестве примеров запросы «купить хороший диван» и «магазины диванов», то можно прогнозировать, что количество запросов (частота) будет выше для одного из них. Соответственно, чтобы поисковые системы отображали ваш ресурс в результатах поиска, необходимо добавить в информацию интернет-магазина, торгующего диванами, ключ «Купить красивый диван».
Семантическое ядро или семантика — это список множества типов запросов, обычно разбитых на группы по определенному типу. Такая группировка называется кластеризацией, и почти все специалисты кластеризуют семантику, то есть делят их на группы. Это поможет вам не только составить хороший ТТ, но и точно определить, какие типы запросов продвигать.
Методы построения семантического ядра
Сборщик ключей
Для построения семантики можно использовать программы, предназначенные для построения семантического ядра. Некоторые из них делают за вас практически всю работу — такие программы называются автоматическими. В некоторых программах вам придется работать более самостоятельно.
Например, есть платная программа Key Collector. Хотя эта программа почти полностью автоматизирована, вам нужно знать, как настроить Key Collector. Как только вы запустите его, эта программа сделает все автоматически. Нужно только удалить самые бесполезные из ключей по окончанию работы, то есть немного почистить запросы, в очистку входят запросы от роботов, спам и т.д. Стоимость такой программы почти 2000 рублей.
Яндекс Вордстат
Также можно собирать семантику с помощью сервиса Яндекс — Wordstat. Он очень прост в использовании, вы вводите ключевое слово и нажимаете кнопку поиска, он покажет вам все запросы, содержащие это ключевое слово. В то же время Wordstat также отображает запросы, похожие на первичный ключ.
В этой статье мы соберем исходные запросы, необходимые для построения базового семантического ядра с помощью Wordstat. Об этом позже, а пока расскажу еще несколько способов сбора семантики.
Яндекс Вордстат + СловоЙоб
СловоЁб — это полностью бесплатный аналог Key Collector, программы с таким древним названием. Функционала у него, естественно, чуть меньше, чем у KeyCollector, но для сбора семантического ядра и этих функций достаточно.
Если вы хотите узнать, чем СловоЁб отличается от Key Collector, посмотрите эту таблицу:
Конечно, здесь разница между землей и небом. Однако возможностей СловоЁба достаточно для сборки простого ядра.
Онлайн-сервисы
Таким образом, кроме вышеперечисленных вариантов, также возможен сбор семантики с помощью онлайн-сервисов. Если вы введете в поисковик запрос «Сбор семантики онлайн», то поисковик покажет вам различные виды онлайн-инструментов. Они могут быть как хорошими, так и плохими. И соответственно как платные, так и бесплатные.
С помощью различных онлайн-сервисов можно узнать семантическое ядро ваших конкурентов. Практически все компании мира проверяют и анализируют открытые данные своих конкурентов.
Заказ специалистов
Купить готовый сердечник можно у специалиста. Специалист собирает все запросы и отправляет вам файл с собранными запросами. И на основе ключевых слов в этом файле составляется техническое задание (ТЗ) для написания статьи. И готовое ТЗ отдается копирайтеру для написания статьи. Теперь дело за распределением рабочих мест. Мы обсудим эту тему b
Не будем его касаться, рассмотрим в другой статье.
Нужно ли структурировать семантику?
Если вы читаете эту статью, значит вас тоже интересует этот вопрос. Сбор семантики поначалу кажется сложной задачей. Кроме того, некоторые веб-мастера не всегда понимают, зачем это нужно.
Если речь идет о блоге или сайте, созданном для заработка, то у авторов таких проектов возникает резонный вопрос: «где черпать вдохновение и о чем писать». Если у вас есть готовая электронная таблица со всеми вашими темами и ключевыми словами, то вы точно знаете, о чем писать свой материал. Такой подход позволяет не только замедлить скорость, но и увеличить ее, ведь вам не придется беспокоиться о теме следующей статьи. Остается только выбрать одну из тем из списка и решить, как написать материал самостоятельно.
Таким образом, все ваши статьи (если текст написан правильно, ключевые слова расставлены и правильно использованы) будут хорошо ранжироваться в поисковых системах, что увеличит количество посетителей вашего проекта, обеспечивает и повышает ваш интерес, мотивируя вас на достижение новых цели. Счастливый, верно? Все эти радости связаны с одним элементом, сборка которого не требует много времени: семантикой.
Если говорить о коммерческих сайтах (кредитование, интернет-магазины и т. д.), сбор семантического ядра — необходимость. Откровенно говоря, без семантики иначе никак, такой сайт лучше не открывать. Как при наполнении ресурса контентом и метатегами, так и при предоставлении контекстной рекламы нам обязательно нужна семантика, только от этого зависит развитие нашего бизнеса.
Одного СловоЁба недостаточно, чтобы собрать всю семантику. Если мы хотим полноценно развивать свой бизнес и полностью структурировать семантику, нам необходимо приобрести расширенную версию СловоЁб под названием Key Collector. В программе много разных функций, предназначенных для работы с разными контекстными сетями (Директ, Адвордс и т.д.) (как видно из таблицы выше).
В заключение стоит построить семантику. Это повысит качество продвижения вашего проекта и позволит гораздо лучше получать информацию о потребностях пользователей при планировании контента.
Как правильно построить семантическое ядро шаг за шагом?
Попробуем построить семантическое ядро за пять шагов. К ним относятся: поиск и подбор основных ключевых слов, анализ их в программе SlovoEB или Key Collector (я использую первый вариант), определение частоты по каждому запросу (сколько раз он запрашивался), дополнений (хвоста), т.е. , дополнительные запросы, содержащиеся в основном ключевом слове.
Например: «Купить черный диван онлайн в Ташкенте», где жирным черным выделен первичный ключ, а все остальные слова в запросе — хвосты. Если наши статьи включают не только основной запрос, но и их хвосты, то пользователи могут найти именно этот наш материал по различным вариантам этих фраз.
Итак, приступим к построению семантики шаг за шагом…
Сбор начальных отмычек
Мы используем Wordstat для сбора исходных первичных ключей. Но перед этим нам нужно самостоятельно определиться, на какие темы писать статьи или продвигать. Для себя пишу следующие темы:
Зарабатывать
доход,
финансы,
фрилансер,
написать статью.
Я думаю, 5 будет достаточно, чтобы сделать пример. В вашем случае этих тем может быть больше. При сборе исходных первичных ключей можно использовать заголовки разделов сайта или заголовки статей, которые будут написаны в этих разделах.
Теперь берем первое слово и помещаем его в [mask_link]Wordstat[/mask_link]. Сервис показывает нам большое количество разных запросов с их частотой (сколько раз они были найдены), то есть количество запросов, сделанных в поисковой системе Яндекс именно с этими словами. Это выглядит так:
Как видите, здесь вариантов много. Сервис показал нам самые популярные запросы, связанные со словом зарабатывать деньги. И с правой стороны он также показал нам похожие варианты, которые могут нам понравиться.
Итак, остановитесь здесь и напишите статью, используя такие ключевые слова, как «заработать деньги в Интернете», «как заработать деньги», и тысячи читателей стекаются, чтобы прочитать наш шедевр. Подождите, это определенно большая ошибка.
Кстати, установите этот плагин в свой браузер:
Этот плагин позволяет работать с Wordstat
перечисляет. После того, как вы настроите его, рядом с ключевыми словами появится значок (+). Какой бы ключ вам ни понравился, нажмите (+) на этом ключевом слове, и ключевое слово появится в окне плагина слева. И как только вы получите все хорошие ключи, вы сразу скопируете все ключи в окно и сохраните их в отдельном файле. В противном случае вам придется взять один:
Итак, вернемся к теме…
Итак, построить семантическое ядро не так просто, как мы думаем, ключи, приведенные в Вордстате выше, являются высокочастотными ключами. С такими ключами мы не можем занимать высокие места. И не будем оставлять без внимания, самая эффективная разработка — это равноправное использование всех типов ключевых слов.
Теперь соберем все остальные исходные ключевые слова, которые мы придумали, в один файл, точно так же, как мы использовали ключевое слово «Монетизация», а также связанные с ними запросы. Мы также можем собрать то, что нам нужно, из запросов в правом окне Wordstat.
После первого шага у нас должен получиться список из нескольких десятков самых вкусных запросов, на наш взгляд и по данным Wordstat. Старайтесь выбирать вопросы, понятные с точки зрения письма. Я не думаю, что здесь должны быть какие-то проблемы.
Наш список должен выглядеть примерно так:
Собирайте ключевые запросы с помощью СловоЁб / Key Collector
Теперь перейдем к самому интересному. С помощью СловоЁб или КейКоллектор нам нужно собрать суффиксы и синонимы всех основных запросов в разных формах.
Учитывая, что не у всех есть KeyKollektor, то все сделаю в СловоЁбе. Сначала скачайте программу [mask_link]здесь[/mask_link] и установите ее на свой компьютер, затем настройте программу.
Для настройки нам нужно открыть новую почту Яндекс и ввести данные для входа в нашу почту в специальное место в СловоЙоб. Цель открытия новой почты в том, что даже если Яндекс пришлет нам почту, наша новая почта будет почтой. Нужную почту лучше не вводить сюда.
Настройте его согласно изображению ниже, между логином и паролем поставьте двоеточие, например, логин:пароль, введите его таким же образом и нажмите кнопку «Сохранить изменение» ниже:
Итак, продолжим…
После установки и настройки программы откройте новый проект с помощью кнопки в главном окне или в верхнем меню:
После создания проекта необходимо начать сбор семантики через Вордстат (кнопки обозначенные цифрой 1 на картинке ниже, красная кнопка собирает данные из левого столбца Ворстата и синяя кнопка из правого столбца, кнопка три кружка собирает дополнительные ключи). Короче говоря, программа сама подключается к Wordstat и собирает все необходимые данные, вам достаточно нажать нужную кнопку.
Обратите внимание (изображение выше), что мы используем левый столбец Wordstat для агрегирования. В левой колонке расположены основные ключевые слова всех сайтов в поисковых системах. Но мы также можем собрать правую колонку. Таким образом мы собираем огромное количество ключевых слов разного рода.
Итак, вносим все ключи в файл, где хранятся исходные ключевые слова, собранные из Wordstat, в открывшемся окне программы и нажимаем кнопку «Сохранить».
Процесс запускается, и программа начинает поиск запросов, содержащих нужные фразы. Конечно, чем больше ключевых слов вы введете в окно, тем больше ключевых слов мы сможем собрать. Однако чем больше ключей введено в окно, тем дольше может длиться работа программы. Может работать 2-3 часа, иногда даже сутки. Итак, чтобы сэкономить время, я оставил одну заявку «Заработок в Интернете» и запустил процесс. Вот что мне выдала программа:
Как видите, программа сделала свое дело и я получил не только разные запросы, но и их частоту. Однако не спешите радоваться. Информация, отмеченная красным прямоугольником, может оказаться совершенно бесполезной или неверной. Эти частоты также называются холостыми или базовыми частотами.
Если вы напишете статью, используя базовую частоту здесь, через несколько месяцев статью никто не прочитает. Поэтому нам необходимо получить реальные данные, для этого мы используем внутренние функции программы.
Получение фактической частоты
Что такое частота – сколько раз пользователи задают каждый запрос.
Чтобы получить актуальную частотность ключевых слов и словосочетаний, мы можем воспользоваться встроенными функциями СловоЁб или Коллектор ключей. Поскольку в этой статье мы используем СловоЙоб, я объясню все на его примере. В Key Collector этот процесс почти не отличается.
В новых версиях изменилось только расположение элементов. Но я уверен, что ты разберешься.
В СловоЁбе мы используем следующие кнопки, нам нужна нижняя:
» » – соответствует частоте только слов, заключенных в двойные кавычки. Дополнение и расположение могут быть разными.
! – Точный ключ доступа, который не меняет частоты, суффикса и позиции слова.
Отмечаем все ключи галочкой «Сбор частотност»!» » и получаем следующие частоты:
Вы сами видите разницу между двумя столбцами. Фактическая частота запроса «Заработок в Интернете» почти в 1 раз меньше базовой частоты (первая колонка). Это может быть более заметно в других опросах. Поэтому каждый раз при сборе семантики обязательно используйте программы, определяющие реальную частоту.
Очистка запросов позволяет получить достоверную информацию о частоте запросов от пользователей Яндекса.
После процесса получения точных данных вы можете с помощью быстрого фильтра найти ненужные, то есть запросы вообще без частоты или очень мало (до 10) и переместить их в отдельную папку (эта функция отсутствует в СловоЙоб). ). Или вы можете сделать это вручную.
Нам нужны ключевые слова, которые приносят много трафика. Если ваш сайт еще молодой, не спешите получать высокочастотные ключи, которые используют многие популярные сайты. Таких частот может быть больше 1000.
Разумеется, мы также проверяем конкурентоспособность всех запросов. Однако если частота запросов составляет несколько десятков тысяч, то конкурентов по этому запросу будет слишком много.
Кластеризация запросов
Как я уже говорил, ядро — это список многих типов запросов, обычно сгруппированных по типам. Разделение на группы называется кластеризацией.
Теперь нам нужно разбить все наше семантическое ядро, а точнее ключи в нем, на группы. Я буду в рамках данного материала, только по частоте, самый популярный вариант и используемый практически повсеместно. Кроме того, возможно разделение на группы по содержанию и конкурентоспособности.
Мы можем разделить все слова и фразы на высокочастотные (YCH), среднечастотные (O’CH), низкочастотные (PCH) и микронизкочастотные (MPCH). Думаю, нет необходимости объяснять принцип группировки. Однако следует указать приблизительные размеры. В Рунете эти показатели примерно такие:
YCH — высокая частота — более 10 000 запросов (в месяц);
OFF – средняя частота – от 1000 до 10000;
ПЧ – низкочастотный – до 1000;
МЧЧ – микро НЧ – до 100.
У нас может быть меньше населения и людей, которые говорят по-узбекски и ищут информацию на узбекском языке в Интернете по сравнению с пользователями Рунета. По моим приблизительным наблюдениям это может быть:
YCH – высокая частота – более 1000 запросов (в месяц);
OFF – средняя частота – от 500 до 1000;
ПЧ – низкочастотный – до 500;
МЧЧ – микро НЧ – до 50.
Цифры обычно считаются весьма субъективными и приблизительными. Если есть недоброжелатели этих указателей, пишите свои варианты в комментариях.
Группировка по частоте выглядит как сочетание всех запросов, сгруппированных вместе в зависимости от того, сколько раз пользователи выполняли поиск. Мы собрали их на предыдущем шаге, теперь нам просто нужно разделить их на группы.
Здесь можно разделить еще несколько групп, исходя не из частоты запросов, а исходя из конкуренции, то есть количества сайтов, продвигающих эти запросы.
Различают высококонкурентные (YR), среднеконкурентные (OR) и низкоконкурентные (PR) запросы. Мы можем просто так разделить все запросы на разные группы, и это будет еще лучше. Нам нужны максимально частотные и наименее конкурентные запросы для более эффективного продвижения нашего сайта. Конечно, это идеально.
Вы можете использовать автоматизированные инструменты (онлайн-сервисы) для группировки запросов, а можете сделать это самостоятельно.
Сами подумайте, вручную обрабатывая тысячи запросов – можно сойти с ума – это невозможно, тем более, в 21 веке. В целях экономии нервов рекомендую использовать автоматические сервисы для группировки всех ключевых слов.
Таких сервисов в Интернете не так много. Очень хороших еще меньше. На данный момент я хотел бы порекомендовать вам Mutagen, один из самых популярных сервисов по сбору и кластеризации семантики в Рунете уже несколько лет. С его помощью можно выполнять все вышеперечисленные задачи с избытком.
Этот онлайн-сервис платный, но его можно использовать бесплатно с некоторыми ограничениями.
Не более 10 проверок в день. Даже если вы используете платную версию, это не будет стоить вам много. 100 проверок стоят всего 30 рублей, а повторные проверки вашего однажды проверенного запроса бесплатны.
Не должно быть проблем с использованием мутагена. Там все понятно, но интерфейс на русском языке. Также есть небольшой FAQ, объясняющий основы работы с этим сервисом. Если возникнут какие-то недоразумения, если напишите в комментариях, могу написать отдельную статью об этом сервисе.
Для более быстрой кластеризации следует использовать массовую проверку. Мы не проверяем тысячи запросов один за другим. Для проведения публичной проверки необходимо [mask_link]зарегистрироваться на сервисе[/mask_link] и только после этого можно проводить публичную проверку.
После того, как вы получите всю конкурентную информацию в СловоЁб, вы копируете ключи, закидываете их в Мутаген и группируете.
Поиск дополнительного запроса (хвост, хвост).
Наконец, после того, как мы собрали самые вкусные ключи, мы должны попытаться (дополнительно) поискать хвосты. Вводим нужный запрос в Яндекс и Гугл, а они сами нам все показывают, например:
Как видите, не так уж и много. Вы можете сказать, раз мало, то надо ли, действительно умный Яндекс не выставит наш ресурс в ТОП с дополнительными запросами?Если да, то ваш сайт наверняка будет в числе первых ТОП-3 по результатам этих запросов.
Продвижение с дополнительными запросами особенно актуально для молодых сайтов. Потому что таким источникам все равно не доверяют, но если где-то в статье есть ключ, может Яндекс и Гугл могут причислить даже ненадежный источник. Для поисковых систем важно, чтобы каждый пользователь получал именно ту информацию, которую ищет. Поэтому стоит добавить хвостовые запросы в свое семантическое ядро.
К сожалению, сбор хвостов приходится производить вручную. Но не стоит пытаться анализировать хвосты тысяч ключей. Делайте это выборочно, помня о том, что может быть интересно вашим посетителям.
Краткое содержание
Как видите, собрать семантическое ядро можно всего за 5 шагов. Конечно, это руководство содержит базовую информацию, которая поможет вам изучить основы и построить простейшую семантику. Но для очень серьезных проектов требуется соответствующий подход. Например, при кластеризации ключевых слов нужно разделить их не только на YCH и MPCH или YR и PR, но и на коммерческие и некоммерческие. Или вы даже можете разделить на группы в зависимости от региона.
Все это, конечно, занимает много времени, но если вы самостоятельно соберете семантику, проанализируете ее и узнаете, как вообще устроены дела в поисковых системах, то со временем постепенно придете к пониманию того, что начинает приходить. Вы найдете все новые инструменты для различных процессов, сможете собрать семантику и сгруппировать их быстро без каких-либо затруднений. Конечно, если вам это очень интересно.
На этом сегодняшняя статья окончена, если вам что-то непонятно, пишите в комментариях, я обязательно постараюсь объяснить. Возможно соберу все вопросы и напишу отдельную статью. Пока-пока!





